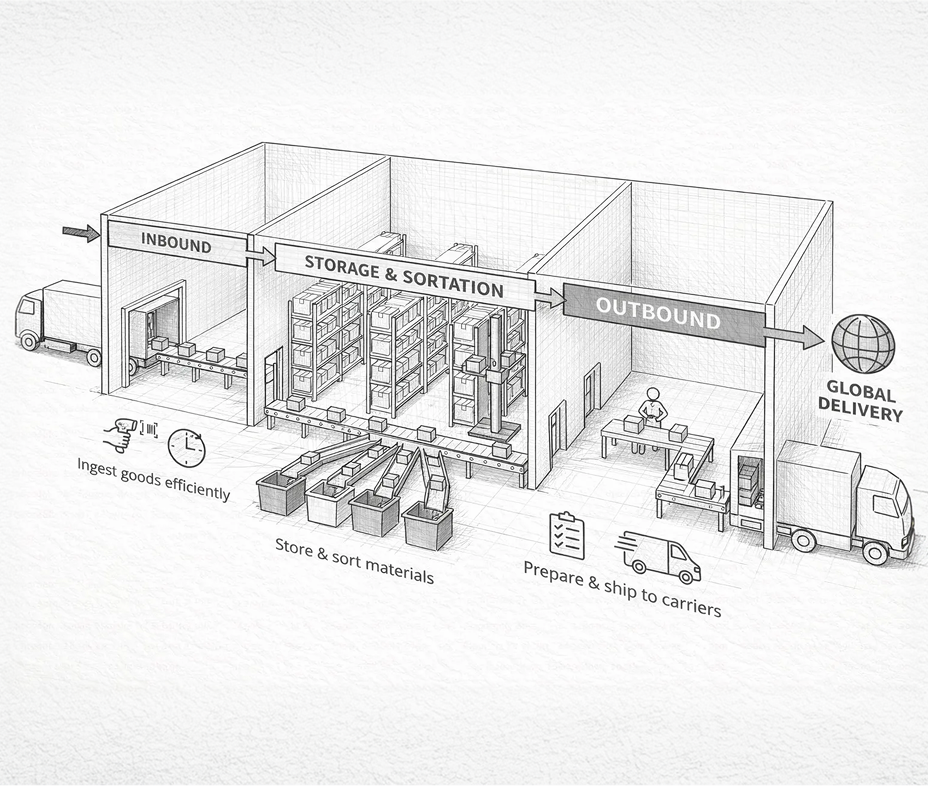
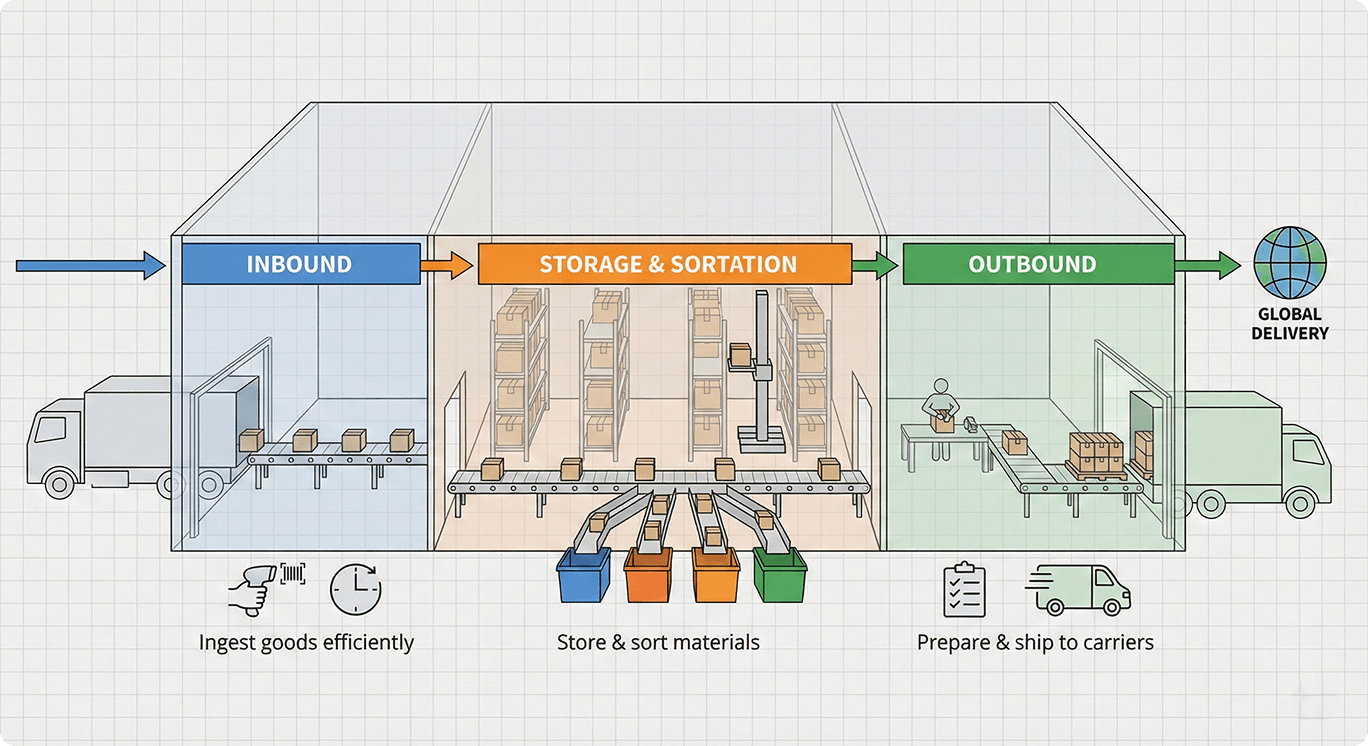
Why this problem exists at all

What “perfect sequencing” really means
- The pallet algorithm outputs a specific arrival order.
- The upstream system must deliver that order precisely.
- Any deviation becomes an exception—often costly to absorb.

Why perfect sequencing was necessary
The stacking problem is algorithmically complex, and rule-based systems cannot adapt
Mixed-case palletizing has a combinatorial explosion: many SKUs, many constraints, many feasible-but-bad options. Historically, many systems relied on rule-based templates—heuristics that produce a suboptimal but stable pallet if the input matches the assumptions.
The downside is rigidity. Once a rule-based planner commits to a plan, it often cannot replan quickly when a wrong case arrives or a dimension drifts; recomputing can be slow and disruptive, and every replan risks throughput loss and operational instability. This "fixed sequence" dependence is part of why older approaches were brittle.
You need store-friendly pallets that follow business rules
Even if you could stack "anything," the pallet must satisfy the rules your network runs on: crush limits, heavy-to-light logic, aisle- or store-friendly grouping, stop sequencing, label orientation, carrier rules, and more.
This is the eggs-before-bricks problem: you can't just minimize travel or pick whatever is convenient; the order in which cases arrive changes what is possible to build without violating rules or damaging product.
Perfect sequencing tries to guarantee that the "right next box" always arrives, so the pallet plan remains valid.

Why perfect sequencing breaks in real warehouses
Lumpy waves make sequencing hard to sustain
Real facilities see uneven flow: bursts from pick-to-belt, release waves, and live-loading variability. Integrators "actually see" imperfect sequencing and lumpy waves as a default condition.
Those waves are not just noise—they change which cases are available when. Maintaining a perfect arrival order under lumpy flow often requires larger buffers and more complex orchestration, which increases cost and failure modes.
Packaging drift and data erosion degrade the plan
Even when a SKU ID is "the same," real cases drift: dimensions, corrugate stiffness, wrap style, label placement, and damage rate. Over time, the data used to generate the sequencing plan becomes less reliable, and what used to be feasible becomes fragile.
Modern systems increasingly emphasize adapting to "SKU drift" rather than assuming static master data.
The system is brittle: tiny disruptions have outsized impact
When the plan depends on "Box #17 must arrive next," then a small disruption—a missing tote, a mis-scan, a short pick, a conveyor stop—can cascade. The palletizer waits, the upstream system scrambles, and the whole chain either slows down or spills into manual exception handling.
This brittleness is why sequenced mixed-case automation has historically been packaged as a mega-project—because you need the entire surrounding system to be engineered to protect sequence integrity.
It is expensive, and few sites can justify it
Even if sequencing can be made to work, the economics are daunting: AS/RS capacity, buffers, controls integration, commissioning, and long-term tuning. Traditional paths assumed a mega-project that "only the top 1% of warehouses could justify."
Conclusion: sequencing was a workaround for a hard stacking problem
Where OmniPalletizer fits